
헬스케어 질의 응답이 가능한 sLLM 파인튜닝하기
프로젝트 개요
안녕하세요, 지난번 Llama-3.2-1B-Instruction 모델을 한국어 QA 태스크에 파인튜닝했던 경험을 공유드렸는데요. 이번에는 AIHub의 초거대 AI 헬스케어 질의응답 데이터를 활용하여 비슷한 프로젝트를 수행한 경험을 공유하고자 합니다.
[지난 Llama-3.2-1B 파인튜닝 프로젝트 보기]
Llama-3.2-1B-Instruction 모델 파인튜닝하기
Llama 모델이란?먼저, Llama 모델에 대해 간단히 소개하겠습니다. Llama(Large Language Model Meta AI)는 Meta AI에서 개발한 대규모 언어 모델입니다. OpenAI의 GPT 시리즈와 마찬가지로 트랜스포
naakjii.tistory.com
이번 프로젝트의 목표는 AIHub에서 제공하는 헬스케어 관련 질의응답 데이터를 사용하여 1B 규모의 언어 모델을 파인튜닝하는 것이었습니다. 하지만 실제 진행 과정에서 몇 가지 흥미로운 문제에 직면했고, 이를 해결하는 과정에서 많은 것을 배울 수 있었습니다.
직면한 문제점과 해결 방법
1. 데이터 정합성 문제
첫 번째로 마주친 문제는 AIHub 데이터의 정합성이 떨어진다는 점이었습니다. 질문과 답변의 매칭이 불가능한 상황이 발생했습니다. 저는 EXAONE-3.0-7.8B-Instruct 모델을 활용하여 답변을 기반으로 새로운 질문을 생성하는 방향으로 문제를 해결하고자 했습니다. 이 모델을 사용하여 주어진 답변을 바탕으로 적절한 질문을 추론하는 Task를 수행시켰으며, 이렇게 생성된 질문-답변 쌍을 이용해 instruction 튜닝이 가능한 형태로 데이터셋을 재구성했습니다.
이 작업의 전체 코드는 다음과 같습니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import os
import json
import glob
from tqdm import tqdm
import random
os.environ["HUGGING_FACE_HUB_TOKEN"] = "your-hf-token"
model_id = "LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct"
# 모델과 토크나이저 초기화
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
def generate_text_with_local_model(prompt, model, tokenizer, device):
messages = [
{"role": "system",
"content": "You are an intelligent assistant that helps users by answering questions using the provided context. Always prioritize using the given context to inform your responses. If the context does not contain the answer, you can respond based on general knowledge, but indicate when the information is not found in the context. Be clear, concise, and informative in your answers."},
{"role": "user", "content": prompt}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True, tokenize=True)
#outputs = model.generate(**inputs, max_length=2048, num_return_sequences=1)
output = model.generate(
input_ids.to(device),
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=1024
)
# # 프롬프트 길이 계산
prompt_length = len(input_ids)
generated_text = tokenizer.decode(output[0])
generated_text = generated_text.split("[|assistant|]")[-1].split("[|endofturn|]")[0].strip()
# 프롬프트 이후의 텍스트만 추출
#generated_text = tokenizer.decode(outputs[0][prompt_length:], skip_special_tokens=True)
#sprint(f"생성된 텍스트: {generated_text}")
return generated_text
#답변에 대한 질문을 생성하는 Task Prompt
def generate_question(answer, model, tokenizer):
prompt = f"""
다음 답변에 대한 적절한 질문을 하나 생성해주세요.
다른 문구는 모두 제외하고 생성한 질문만 알려주세요.
답변:
{answer}
"""
generated_text = generate_text_with_local_model(prompt, model, tokenizer, "cuda")
return generated_text.strip()
def get_all_subfolders(folder_path):
subfolders = []
for root, dirs, files in os.walk(folder_path):
subfolders.append(root)
return subfolders[1:] # 첫 번째 항목(루트 폴더)은 제외
def process_json_files(folder_path, model, tokenizer, output_file):
# 모든 하위 폴더를 재귀적으로 찾기
subfolders = get_all_subfolders(folder_path)
for subfolder in tqdm(subfolders, desc=f"{folder_path} 처리 중"):
all_data = []
json_files = glob.glob(os.path.join(subfolder, "*.json"))
# 각 하위 폴더에서 5개의 파일만 무작위로 선택 (5개 미만이면 모든 파일 선택)
selected_files = random.sample(json_files, min(5, len(json_files)))
for file_path in tqdm(selected_files, desc=f"하위 폴더 처리 중: {os.path.basename(subfolder)}", leave=False):
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
answer = data.get("answer", {}).get("body", "")
if answer:
question = generate_question(answer, model, tokenizer)
simplified_data = {
"question": question,
"answer": answer
}
all_data.append(simplified_data)
# 결과를 JSON 파일에 추가
try:
with open(output_file, "r", encoding="utf-8") as f:
existing_data = json.load(f)
except FileNotFoundError:
existing_data = []
existing_data.extend(all_data)
with open(output_file, "w", encoding="utf-8") as f:
json.dump(existing_data, f, ensure_ascii=False, indent=2)
print(f"{subfolder} 폴더의 처리가 완료되었습니다. 총 {len(all_data)}개의 질문-답변 쌍이 추가되었습니다.")
# 메인 실행 부분
output_file = "data.json"
# 처리할 폴더 목록
folders = [
"02.라벨링데이터/2.답변",
]
# tqdm을 사용하여 전체 폴더 처리 진행 상황 표시
for folder in tqdm(folders, desc="전체 폴더 처리 중"):
process_json_files(folder, model, tokenizer, output_file)
print("모든 폴더의 질문 생성이 완료되었고 data.json에 저장되었습니다.")2. 중복 데이터로 인한 성능 저하
앞서 생성한 데이터를 이용해 파인튜닝을 수행했지만 두 번째 문제가 발생했습니다. 동일 카테고리에 답변들에 대해서 질문을 생성하다보니 중복된 instruction이 발생하였지만, 저는 이를 그대로 튜닝에 사용했습니다. 이로 인해 모델의 답변이 반복되는 문제와 전반적인 정확도가 떨어지는 현상이 나타났습니다.
이 문제를 해결하기 위해 데이터 전처리 과정을 한 단계 더 추가해 중복된 instruction을 제거했습니다. 간단해 보이지만 효과적인 해결책이었습니다.
이 작업의 코드는 다음과 같습니다.
import json
# JSON 파일 읽기
with open('data.json', 'r', encoding='utf-8') as file:
data = json.load(file)
# 중복 제거를 위한 딕셔너리 생성
unique_questions = {}
# 중복 제거 로직
for item in data:
question = item['question']
if question not in unique_questions:
unique_questions[question] = item
# 중복이 제거된 데이터를 리스트로 변환
unique_data = list(unique_questions.values())
# 결과를 새로운 JSON 파일로 저장
with open('data_unique.json', 'w', encoding='utf-8') as file:
json.dump(unique_data, file, ensure_ascii=False, indent=4)
print(f"원본 데이터 개수: {len(data)}")
print(f"중복 제거 후 데이터 개수: {len(unique_data)}")
파인튜닝
파인튜닝은 기존과 동일하게 LoRA 방법을 이용하였으며, step 수를 1,000번으로 줄여 adapter를 저장했습니다.
파라미터는 다음과 같습니다.
training_params = TrainingArguments(
output_dir="/results",
per_device_train_batch_size=4, # 기본값은 8
gradient_accumulation_steps=4, # 기본값 1
optim="paged_adamw_32bit",
logging_steps=5,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=1000,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=lora_config,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_params,
packing=False,
)
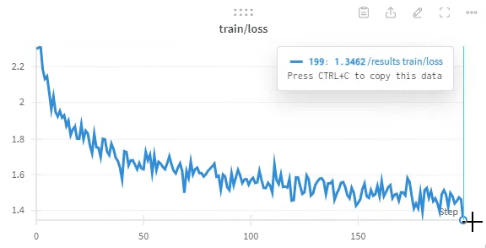
테스트
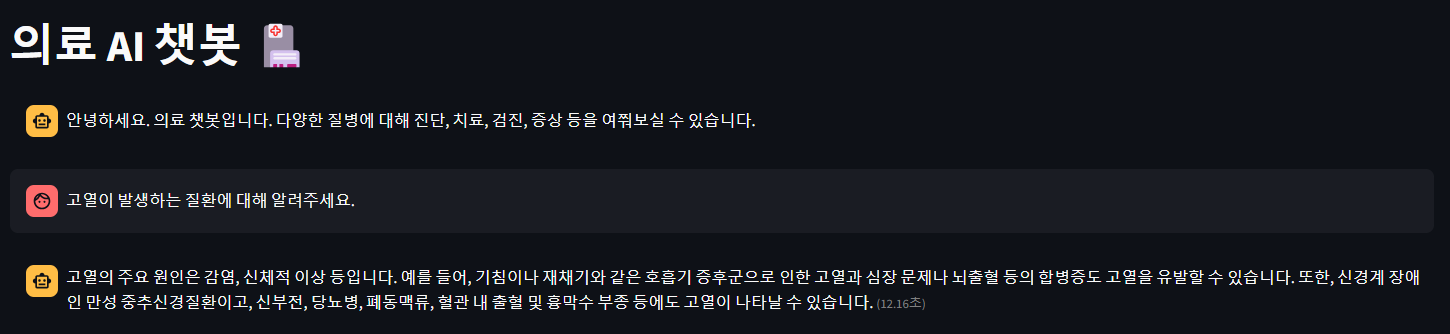
모델과 싱글턴 대화를 주고받을 수 있도록 하기위해 streamlit을 이용했습니다.
테스트는 link 에서 직접 해보실 수 있습니다.
Streamlit
aicse.sch.ac.kr
테스트 결과는 다음과 같습니다.

마치며
아주 작은 모델을 이용할 때에는 적절한 Task를 정의하고 특화된 데이터를 학습시키는 것이 중요합니다.
또한 그 데이터의 품질이 모델 성능에 얼마나 큰 영향을 미치는지를 이 프로젝트를 수행하며 다시 한 번 깨달을 수 있었습니다. 또한, 대규모 언어 모델을 활용하여 데이터셋 자체를 개선하는 방법도 효과적일 수 있다는 점을 배웠습니다.